Basics on Arrayed-NMR Data Analysis (Part IV)
Next up in my survey on
analysis of arrayed NMR experiments ( View Parts
1,
2,
3 ) takes me to a quick overview of the different methods of data evaluation, such as the determination of peak heights and peak areas from arrayed experiments. Here you go...
Of the different existing methods for the extraction of peak intensities from arrayed NMR spectra (see [1] ), Mnova provides the following ones:
(1) Peak area integration
This is the default method in Mnova Data Analysis module (see figure below)
This method consists of a standard numeric integration over the whole peak. Basically, the program is summing up all the points within the selected area of interest) as illustrated in the figure below:
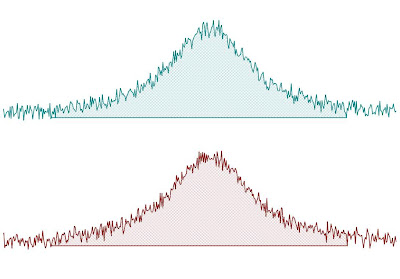
This figure has been created as follow: two identical Lorentzian lines (green & red) were simulated and then noise was added. The noise level is the same in both spectra but obviously, the actual numbers are different (more technically, noise in both spectra was calculated using a different seed in the random number generator).
This peak area method for data extraction is quite robust to noise (provided that the noise level is more or less constant across the different spectra in the arrayed experiment) and more importantly, insensitive to chemical shift fluctuations from trace to trace in the experiment, a situation which is more frequent than generally realized. For these reasons, and for its simplicity of use, this is method of choice for well-resolved peaks.
If the peaks of interest exhibit some degree of overlap, this method is not very reliable and some of the next methods will be more convenient
(2) Peak Height Measurement
This is the second method for data extraction (see figure below) and it finds the peak height at a given chemical shift across all the spectra in the arrayed experiment.
By default, the program will find the peak intensity at the position indicated by the user (using a vertical cursor) and then it will perform a parabolic interpolation in order to refine the value. In addition, the user can specify an interval in such a way that the program will find the maximum peak within that region. This can be done in 2 different ways:
- i) If you click in the Options button, you can define whether you want to use Parabolic and the interval in which the maximum should be found (in ppm

- (ii) Alternatively, once a peak has been selected, you can change the interval by direct editing of the peak selection model. In the figure below, Im showing how the peak selection model is PeakIntensity. The first number (6.001 in the figure) corresponds to the central chemical shift whereas the second number (0.100 in the figure) represents the interval for the peak maximum search.

Parabolic interpolation is useful because it minimizes the problems caused by the random noise. For example, lets assume that Parabolic interpolation is not used so that peak heights extraction will be done always at the same fixed chemical shift position (see figure below). As described in reference [1] and illustrated in the figure below, when this method is used the values are seen to be quite different in the two cases: here the precision of the measurement will depend strongly on the noise.

Parabolic interpolation and/or measurement of the intensity as the maximum height within a fixed box around the peak will help to minimize the effects of movements on the chemical shift position of the peaks due to, for example, temperature instability, pH changes, etc.
For convenience, Mnova includes the so-called
Pick Max. Peak method which is totally equivalent to the previous one but it allows the graphical selection of the left and right boundaries in which the maximum peak will be searched for.
In a nutshell, peak height measurement can be used in those cases in which peak overlap might represent a problem. However, it should be noted that if for some reasons the line widths of the peaks under analysis change from trace to trace, peak heights will not represent a reliable measurement and peak integrals should be used instead.
In general, I would recommend peak integrals as the most general-purpose method for quantitation of peak intensities in arrayed experiments.
In the next post of these series I will address the problem of exponential fitting useful in relaxation and diffusion experiments.
References:
[1] Viles JH, Duggan BM, Zaborowski E, Schwarzinger S, Huntley JJA, Kroon GJA, Dyson HJ, Wright PE. 2001. Potential bias in NMR relaxation data introduced by peak intensity analysis and curve fitting methods. J Biomol NMR 21:19 (
link)
 More...
More...
Source:
NMR-analysis blog


















 Linear Mode
Linear Mode

